Release: Power Attention
In our previous article, we described symmetric power transformers, an alternative to transformers whose state size can be configured independently of both context length and parameter count. This architecture is as powerful as classic transformers, trains far more quickly at long contexts, and can be implemented efficiently on modern accelerators.
Today, we are open-sourcing Power Attention, a hardware-aware implementation of the core operation at the heart of symmetric power transformers: link to code
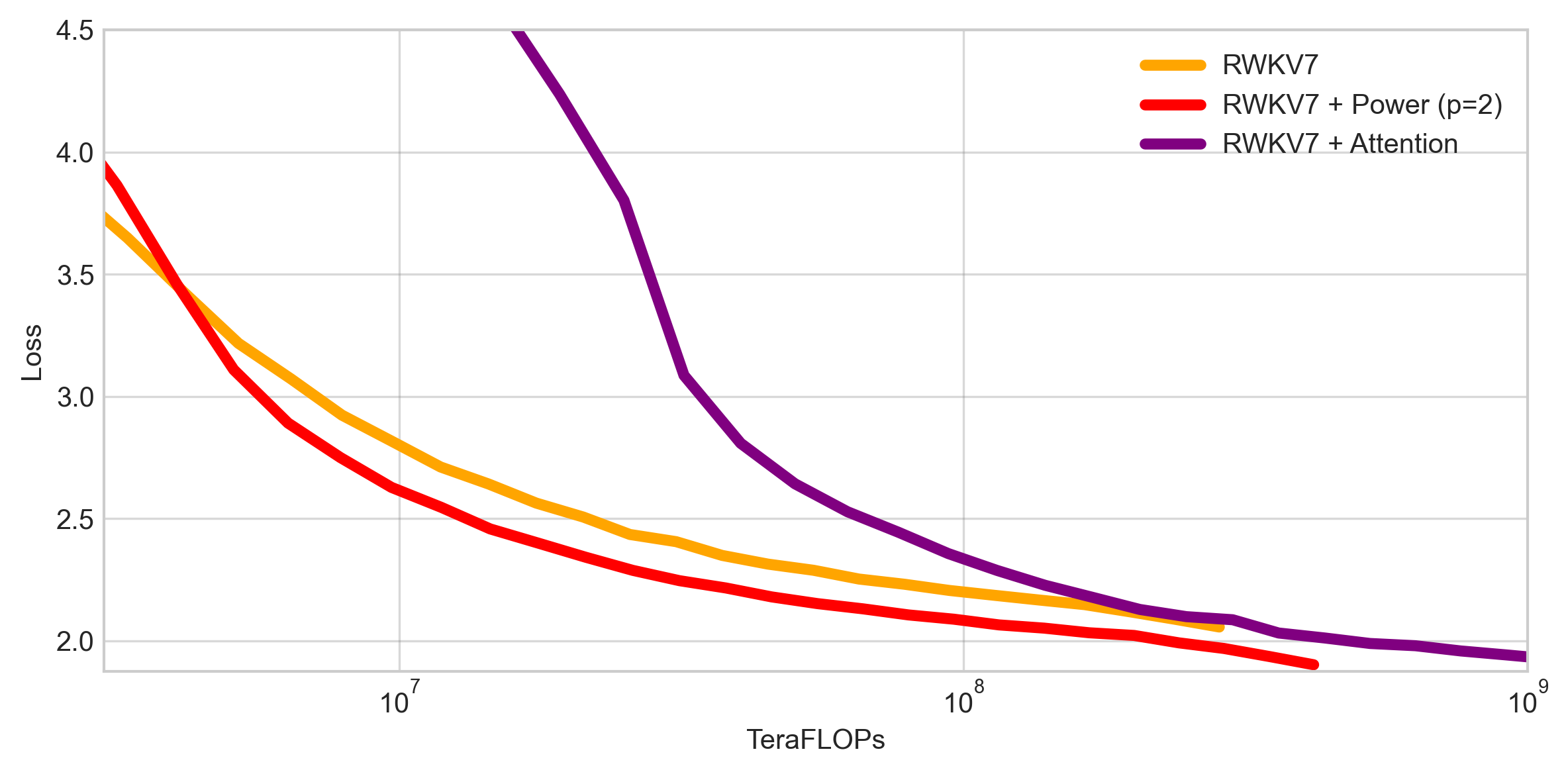
Power Attention provides a drop-in replacement for other forms of attention, including Flash Attention, Linear Attention, or Mamba’s time-mixing. Any sequence architecture can easily be converted into a linear-cost architecture, yielding massive benefits for both training and inference on long contexts. For example, in the figure below, we train a 124M-parameter RWKV7 model on sequences of length 65536 using different attention variants. Power Attention dominates both RWKV’s default linear attention, and “classic” transformer attention, in loss-per-FLOP.
This result comes from our latest research on the learning properties of power attention, published on ArXiv: link to paper
This paper gives a formal exposition of symmetric power attention, and explains why symmetric power transformers are better suited for long-context training than the original transformer. We focus on the weight-state FLOP ratio (WSFR), which measures how the computational work of a model is partitioned between the weights (which contain general information obtained from the dataset) and the state (which contains sequence-specific information obtained from the context). As is often the case, these two must be balanced properly in order to scale well. Models which are too skewed towards either are not compute-optimal.
| Attention | Context Length | WSFR |
|---|---|---|
| Exponential | 1,024 | 8:1 |
| Exponential | 8,192 | 1:1 |
| Exponential | 65,536 | 1:8 |
| Exponential | 1,000,000 | 1:125 |
| Linear | 1,024 | 30:1 |
| Linear | 8,192 | 30:1 |
| Linear | 65,536 | 30:1 |
| Linear | 1,000,000 | 30:1 |
Transformers, whose state is their KV cache, incur state FLOPs proportional to their context length. This translates to a highly skewed WSFR when training at long context. Modern RNNs like RWKV and Mamba, which use linear attention, have the opposite problem: their state FLOPs are independent of context and far smaller than is merited given their parameter counts, leading their WSFR to be skewed towards weight FLOPs at all practical scales. The table to the right summarizes this state of affairs for 120M-parameter architectures. Only one architecture (bolded) has a balanced WSFR.
There are two paths to rectify this imbalance: decrease the state size of exponential attention, or increase the state size of linear attention.
Power attention takes the latter approach. A hyperparameter \(p\), which controls the power of the attention, provides a lever for adjusting the state FLOPs independently of the weight FLOPs. This leads to balanced architectures, good scaling, and efficient learning. Read our paper for more.
In the coming weeks we’ll be releasing speed upgrades and benchmarking results for our kernels, open-sourcing our internal library for writing clean, fast, and generic CUDA code, and digestible summaries of key insights from our paper.
Acknowledgments
We would like to thank SF Compute for supporting this research.